General
PromptBeginner5 minmarkdown
Untitled Skill
193
Podcast prep notes: https://docs.google.com/document/d/1VK5Zs7rYggF0qiceghlR2xtlGgk-g4pkEgJqnsG_sys/edit?usp=sharing
Loading actions...
Main instructions and any bundled files for this skill.
**Published: [https://www.latent.space/p/datasets-101#details](https://www.latent.space/p/datasets-101#details)**
Podcast prep notes: https://docs.google.com/document/d/1VK5Zs7rYggF0qiceghlR2xtlGgk-g4pkEgJqnsG_sys/edit?usp=sharing
WebText and OpenWebText
- GPT-2’s training data is based on Reddit, which according to Pew Internet Research’s 2016 survey, 67% of Reddit users in the US are men, 64% between ages 18 and 29. https://stanford-cs324.github.io/winter2022/lectures/data/
- Common Crawl: https://commoncrawl.org/
- We build and maintain an open repository of **web crawl data** that can be **accessed and analyzed by anyone**.
- January 2015 it was *over 139TB in size* and contains 1.82 billion webpages. https://commoncrawl.github.io/cc-crawl-statistics/plots/crawlsize
- growing steadily at 200-300 TB *per month* for the last few years.
- March 2021: 6.4 PB
- https://commoncrawl.github.io/cc-crawl-statistics/
- [OSCAR corpus](https://traces1.inria.fr/oscar/) from INRIA. OSCAR is a huge multilingual corpus obtained by language classification and filtering of [Common Crawl](https://commoncrawl.org/) dumps of the Web.
- C4: https://paperswithcode.com/dataset/c4
- **C4** is a colossal, cleaned version of Common Crawl's web crawl corpus. It was based on Common Crawl dataset: https://commoncrawl.org. It was used to train the T5 text-to-text Transformer models.
- It comes in four variants:
- `en`: 305GB in JSON format
- `en.noblocklist`: 380GB in JSON format
- `en.noclean`: 2.3TB in JSON format
- `realnewslike`: 15GB in JSON format
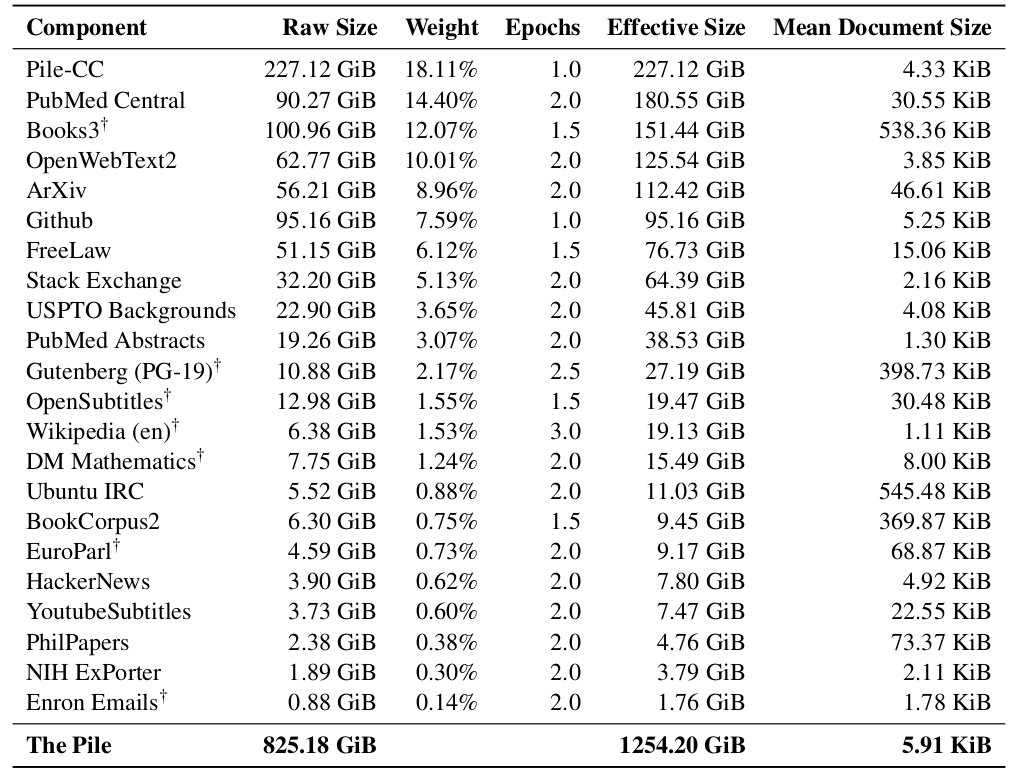
- The Pile: https://arxiv.org/abs/2101.00027
- an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources
- behind the scenes of the collection https://news.ycombinator.com/item?id=34359453
- 
- [Books3](https://www.wired.com/story/battle-over-books3/) lawsuit and copyright issues. [discussion](https://news.ycombinator.com/item?id=37379297)
GitHub code data
- The size of all code/history on Github public repos is 92TB The size of Google's monorepo in 2015 was 86TB (of much higher quality code) If Google were willing to deploy code models trained on their own data, they'd have a noticable advantage over everyone else. https://twitter.com/amanrsanger/status/1656696500339249153
GPT3 data https://stanford-cs324.github.io/winter2022/lectures/data/#gpt-3-dataset
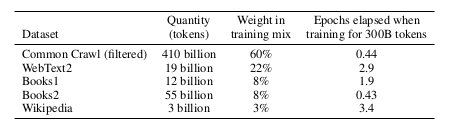
C4 dataset
- The Multimodal-C4 dataset is an expansion of the text-only [C4 dataset](https://www.tensorflow.org/datasets/catalog/c4), which was used to train [T5 models](https://arxiv.org/abs/1910.10683). For each document in the [C4 en.clean](https://www.tensorflow.org/datasets/catalog/c4#c4en_default_config) dataset, we retrieve the original webpage from [Common Crawl](https://commoncrawl.org/), then collect the downloadable images. Data cleaning is carried out through deduplication and content filtering, which aims to eliminate non-safe for work (NSFW) and unrelated images, such as advertisements. Additionally, we run face detection and discard images with positive identifications. Finally, images and sentences are interleaved using bipartite matching within a document: CLIP ViT/L-14 image-text similarities serve as edge weights. Multimodal-C4 consists of approximately 75 million documents, encompassing around 400M images and 38B tokens.
llama datasets
- https://agi-sphere.com/llama-models/#Training
- - ** English [CommonCrawl](https://commoncrawl.org/) (67%)**: Removed non-English text and duplicated content. Only includes pages used as references in Wikipedia.
- **[C4](https://huggingface.co/datasets/c4) (15%)**: A cleaned version of CommonCrawl. The same filters were applied.
- **Github (4.5%)**: Public GitHub dataset available on Google BigQuery.
- **Wikipedia (4.5%)**: From June-August 2022 period covering 20 languages.
- **Gutenberg and Books3 (4.5%)**: Both are book datasets.
- **ArXiv (45%)**: Scientific data.
- **StackExchange (2%)**: High-quality Q&As covering science and engineering topics.
## special purpose
FLAN
- dataset like flan, which is a really, really large dataset that is, I think thousand plus tasks.
Images -
- LAION 5B was the original commoncrawl extract that was used for stable diffusion
- only dynamic links to image URLs.
- **LAION400** experienced approximately 20% failure in download after about 2-2.5 years according to a [paper](https://arxiv.org/abs/2111.12359?utm_source=ainews&utm_medium=email) cited by `@flow7450`.
- got taken down due to CSAM content
- DataComp is the new LAION? see latent.space neurips papers coverage
-
alpaca instruction tuning dataset - 53k instructions
https://github.com/tatsu-lab/stanford_alpaca
- alpaca_data.json contains 52K instruction-following data we used for fine-tuning the Alpaca model.
- https://twitter.com/tatsu_hashimoto/status/1635309815315705856?s=20
text to sql
- https://yale-lily.github.io/spider
- https://huggingface.co/NumbersStation/nsql-6B
BigCode dataset
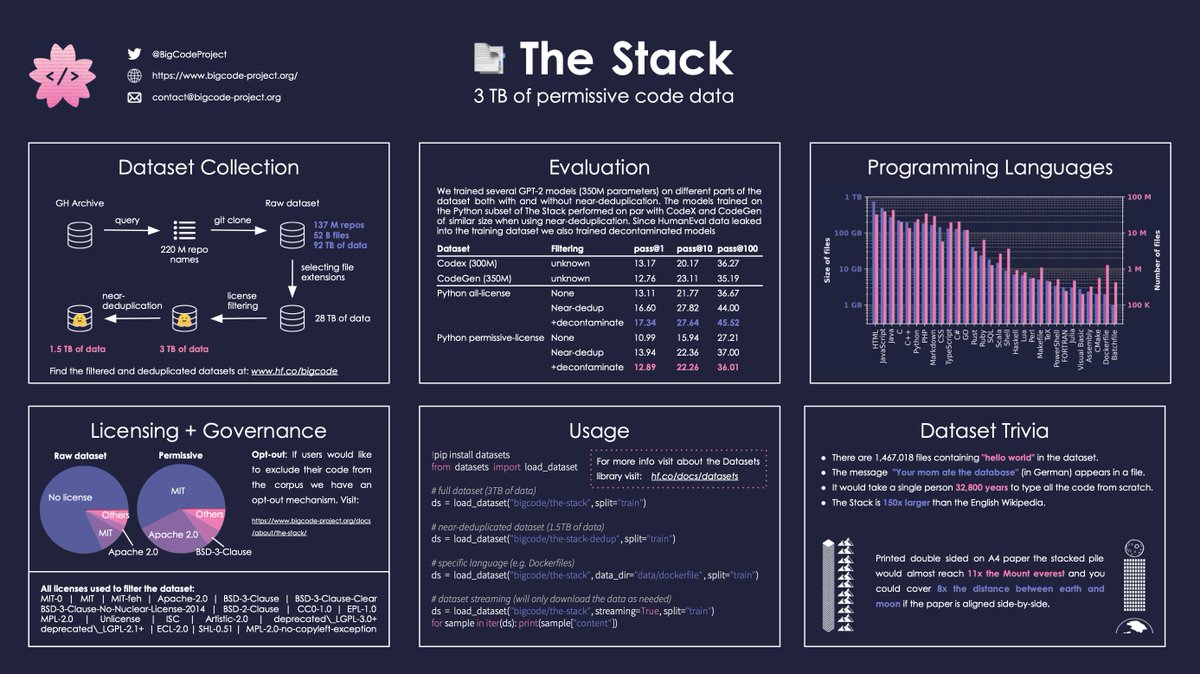 https://techcrunch.com/2023/05/04/hugging-face-and-servicenow-release-a-free-code-generating-model/?guccounter=1
chatbot dataset
- fisher dataset
- language consortium
- The Fisher dataset, also known as the Fisher Corpus or Fisher-Callhome Corpus, is a widely used dataset in the field of automatic speech recognition (ASR) and spoken language understanding. It was created by the Linguistic Data Consortium (LDC) and is primarily focused on conversational speech.
- The Fisher dataset consists of approximately 2,400 two-way telephone conversations between native English speakers. These conversations were collected between 2000 and 2001 and cover a variety of topics, ranging from casual social conversations to more task-oriented dialogues.
- wizards of turns
- 1. Cornell Movie Dialogs Corpus: A dataset containing conversations extracted from movie scripts. It includes a large number of dialogues that can be used for training conversational agents.
1. Microsoft Dialogue Dataset: A collection of multi-turn dialogues sourced from the Microsoft customer support platform. This dataset is designed to enable the development of chatbots that can handle real-world customer service scenarios.
3. Persona-Chat: This dataset, created by researchers at Facebook AI, consists of dialogues where each participant is given a profile (or persona) that they should adopt during the conversation. It aims to improve chatbot responses by incorporating personalization.
4. Ubuntu Dialogue Corpus: A dataset collected from the Ubuntu chat logs, which were recorded during technical support conversations about the Ubuntu operating system. This dataset is useful for training chatbots that can provide technical assistance.
5. Twitter Conversation Corpus: A dataset containing conversations from Twitter. It includes a wide range of topics and conversational patterns found on the platform.
MAD-LAD 400 is a dataset comprising of more than ~400 distinct languages spread across 3 trillion tokens (5 trillion for the uncleaned and therefore noisier dataset). They gathered the dataset by training a LangID model on ~500 languages, then using that model to filter a large Common Crawl corpus, resulting in MAD-LAD 400 noisy. Once they had that dataset, they applied a bunch of quality filtering steps to filter out low-quality or erroneous content. Through this process, they ended up omitting 79 of the languages found in the dataset, reducing the size of the cleaned MADLAD-400 dataset to 419 languages or so.
- **Read the paper**: [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset (arXiv)](https://substack.com/redirect/580fad73-63b4-497b-b3f0-d586cc6892ad?j=eyJ1IjoiMXJpMWl2In0.C0Ak4MTmgoSYyoS5SIGPMgVtwuoX_jfRLexEFRuZ7SI).
**Get the models and data**: [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset (GitHub)](https://substack.com/redirect/8feac410-f81f-4eaa-847d-a72d294ca7d8?j=eyJ1IjoiMXJpMWl2In0.C0Ak4MTmgoSYyoS5SIGPMgVtwuoX_jfRLexEFRuZ7SI).
## voice/audio
- Mozilla https://commonvoice.mozilla.org dataset
- https://news.ycombinator.com/item?id=38535971
## data issues
contamination
- John graaham cumming and paulg discussion https://twitter.com/jgrahamc/status/1635688698036596763?s=20
Label errors
- https://labelerrors.com/
- https://dcai.csail.mit.edu/
- https://www.youtube.com/watch?v=ayzOzZGHZy4&list=PLnSYPjg2dHQKdig0vVbN-ZnEU0yNJ1mo5
labelers cheating https://arxiv.org/abs/2306.07899
- We reran an abstract summarization task from the literature on Amazon Mechanical Turk and, through a combination of keystroke detection and synthetic text classification, estimate that 33-46% of crowd workers used LLMs when completing the task.
running out of data - repeat it? https://twitter.com/XueFz/status/1660867457903632385
data going dark
- stackoverflow data dump https://news.ycombinator.com/item?id=36257523
- reddit api monetization
TypeScript and ESLint rules that MUST be followed when creating, modifying, or reviewing any file under apps/frontend/, including .ts, .tsx, .js, and .jsx files. Also apply when discussing frontend li...
risks
Published: https://www.latent.space/p/datasets-101#details
Podcast prep notes: https://docs.google.com/document/d/1VK5Zs7rYggF0qiceghlR2xtlGgk-g4pkEgJqnsG_sys/edit?usp=sharing
WebText and OpenWebText
en: 305GB in JSON formaten.noblocklist: 380GB in JSON formaten.noclean: 2.3TB in JSON formatrealnewslike: 15GB in JSON format
GitHub code data
GPT3 data https://stanford-cs324.github.io/winter2022/lectures/data/#gpt-3-dataset

C4 dataset
llama datasets
FLAN
Images -
@flow7450.alpaca instruction tuning dataset - 53k instructions https://github.com/tatsu-lab/stanford_alpaca
text to sql
BigCode dataset
chatbot dataset
Microsoft Dialogue Dataset: A collection of multi-turn dialogues sourced from the Microsoft customer support platform. This dataset is designed to enable the development of chatbots that can handle real-world customer service scenarios.
Persona-Chat: This dataset, created by researchers at Facebook AI, consists of dialogues where each participant is given a profile (or persona) that they should adopt during the conversation. It aims to improve chatbot responses by incorporating personalization.
Ubuntu Dialogue Corpus: A dataset collected from the Ubuntu chat logs, which were recorded during technical support conversations about the Ubuntu operating system. This dataset is useful for training chatbots that can provide technical assistance.
Twitter Conversation Corpus: A dataset containing conversations from Twitter. It includes a wide range of topics and conversational patterns found on the platform.
MAD-LAD 400 is a dataset comprising of more than ~400 distinct languages spread across 3 trillion tokens (5 trillion for the uncleaned and therefore noisier dataset). They gathered the dataset by training a LangID model on ~500 languages, then using that model to filter a large Common Crawl corpus, resulting in MAD-LAD 400 noisy. Once they had that dataset, they applied a bunch of quality filtering steps to filter out low-quality or erroneous content. Through this process, they ended up omitting 79 of the languages found in the dataset, reducing the size of the cleaned MADLAD-400 dataset to 419 languages or so.
contamination
Label errors
labelers cheating https://arxiv.org/abs/2306.07899
running out of data - repeat it? https://twitter.com/XueFz/status/1660867457903632385
data going dark
